ios
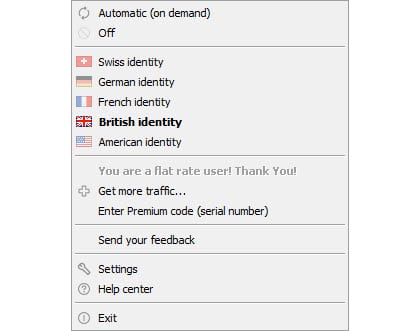
打开选择节点就能连接,无需登录等其他冗余操作。
价格取决于您在注册时选择的位置。
VPN代理使用虚拟专用网络(VPN)技术,通过设备与目标网站之间的加密通道提供了安全可靠的连接。
对上传速度有额外的限制。
app下载
官网
最新版
最新版下载
永久免费
下载
app官网下载
是一款非常好用的网游加速器软件,支持最新最热门的网络游戏加速服务,比如:绝地求生、堡垒之夜、apex英雄等等。
Android版
德民众"躺尸"抗议气候变化
免费下载
外媒:印度尼西亚总统佐科已决定迁都 搬离爪哇岛
允许您从 Windows、Mac 或 Linux 机器进行连接。